



前回アップグレードしたCore i9-13900KFは、その後もmacOS Ventura 13.0で順調に稼働してます。
| IntelのデスクトップPC向け・第13世代CoreプロセッサーRaptor Lake-Sが発売されました。そこで、GPU非搭載版のCore i9-13900KFをmacOS Ventura 13.0で使用し、どれくらいのスコアが出るのか確認しました。マルチコアの結果は、Geekbench 5の場合、M1 MaxとUltraの中間の性能でした。Cinebench R23では、Ultraの1.5倍弱の性能でした。マシン構成使用したマシンは、以下で紹介したASRock Z690 Steel Legend WiFi 6Eを使ったマシンです。macOSはVentura 13.0、OpenCoreは0.8.5で、kext類は最新です。今までは12900Kを使っていましたが、こ... Raptor Lake-S 13900KFの32コアをmacOSで使う - Boot macOS |
この記事へのコメントで、CpuTopologyRebuildというkextを作者の方から教えて頂きました。物理コアとハイパースレッド (HT) の構成をmacOSに伝えるkextです。Alder Lake-Sのために作られて、Raptor Lake-Sでは未検証とのことでしたが、試したところ正しく動作しました。13900K, KFは、Pコア8, HT 8, Eコア16の全32スレッド構成 (8P16E32T) ですが、これを
- 物理コア24, HT 8、全32スレッド (24C32T) または、
- 物理コア8, HT 24、全32スレッド (8C32T)
に見せることが可能でした。ベンチマークテストの結果、マルチコアのスコアはどの構成でも大差はありませんが、シングルコアのスコアは物理コア8 (8C32T) と設定した場合が高性能でした。
Table of Contents
CpuTopologyRebuild.kext
今回試したkextは、以下のCpuTopologyRebuild.kextです。
| Contribute to b00t0x/CpuTopologyRebuild development by creating an account on GitHub. GitHub - b00t0x/CpuTopologyRebuild - GitHub |
Core i9-13900は、Pコア8, HT 8, Eコア16の構成です。macOSがサポートしているインテルCPUには、PコアとEコアが混在するモデルはありません。なので、均一の物理コアとHTの組み合わせとして認識させることになります。OpenCoreそのままで使用すると、全部が物理コアとして扱われて、
- 物理コア32、全スレッド32 (32C32T)
としてmacOSから見えるようになります。ちょっと乱暴な気はしますが、性能もそこそこ良く、特に問題は発生していませんでした。これに対して、CpuTopologyRebuild.kextを使うと、
- 物理コア24, 全スレッド32 (24C32T)、または、
- 物理コア8, 全スレッド32 (8C32T)
のようにmacOSに見せることができました。このkextを有効にすると物理コアが24になり、さらにboot argに-ctrsmtを追加すると物理コアが8コアになります。以下に13900K, KFのコア構成とkextの設定を表で示します。
| 物理コア | 全スレッド | kext | boot arg |
| 32 | 32 | なし | なし |
| 24 | 32 | あり | なし |
| 8 | 32 | あり | -ctrsmt |
コア数を確認する
Geekbench 5の表示で確認すると、確かにコアの構成が変わってます。以下はそれぞれ、32コア、24コア、8コアに設定した場合の表示です。
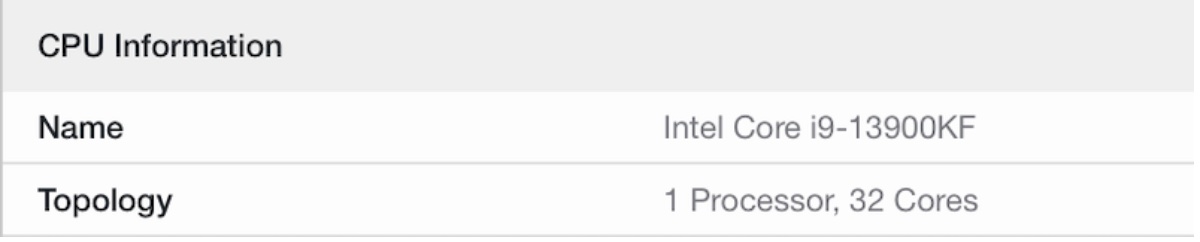

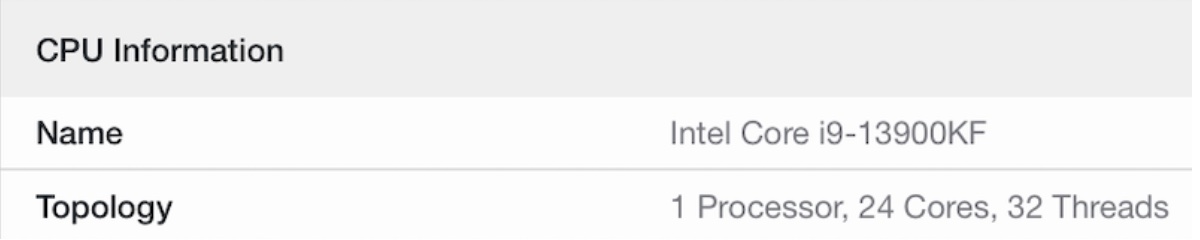

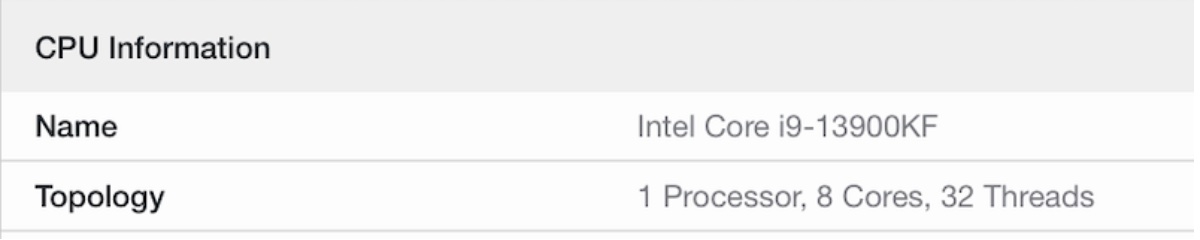
さらに、sysctl -a | grep cpuした結果を、diffで比較しました。<で始まる行がkextなしで、>で始まる行がkextあり(-ctrsmtオプション付き)の項目です。OpenCoreデフォルトだと32コアなところが、このkextで8コアになっていることがわかります。
< hw.perflevel0.physicalcpu: 32 < hw.perflevel0.physicalcpu_max: 32 > hw.perflevel0.physicalcpu: 8 > hw.perflevel0.physicalcpu_max: 8 < hw.perflevel0.cpusperl2: 1 > hw.perflevel0.cpusperl2: 2 < hw.physicalcpu: 32 < hw.physicalcpu_max: 32 > hw.physicalcpu: 8 > hw.physicalcpu_max: 8
Geekbench 5の比較
Geekbench 5のスコアを比較します。数回実施した平均値です。参考に、GeekbenchのサイトにあるM1 Ultraのスコアも加えました。13900は、M1 Ultraにはシングルで勝っているものの、マルチでは負けてます。
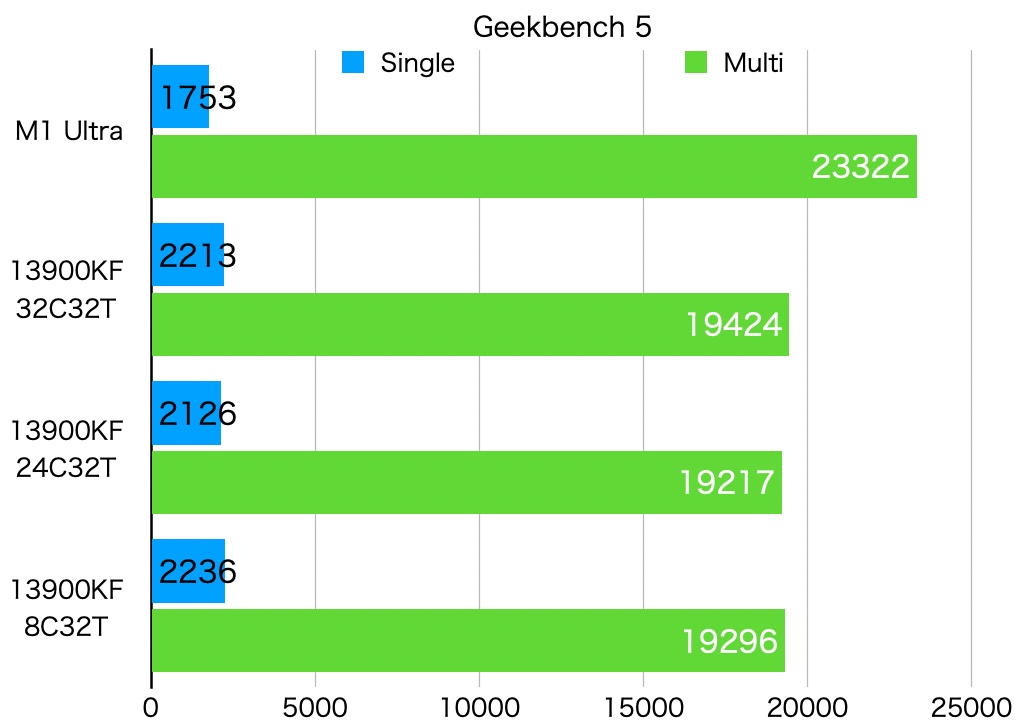

コア構成の比較では、マルチの差は1%以下で誤差に近いです。シングルの差は4%くらいあって、8C > 32C > 24Cの順番で、8Cが一番良いです。
Cinebench R23の比較
Cinebench R23でもベンチマークしました。マルチは数回の平均、シングルは2回の平均です。これもM1 Ultraと比較しましたが、こちらはシングル、マルチとも13900がM1 Ultraよりも高速でした。Intel CPUが得意とするベンチマークのようです。
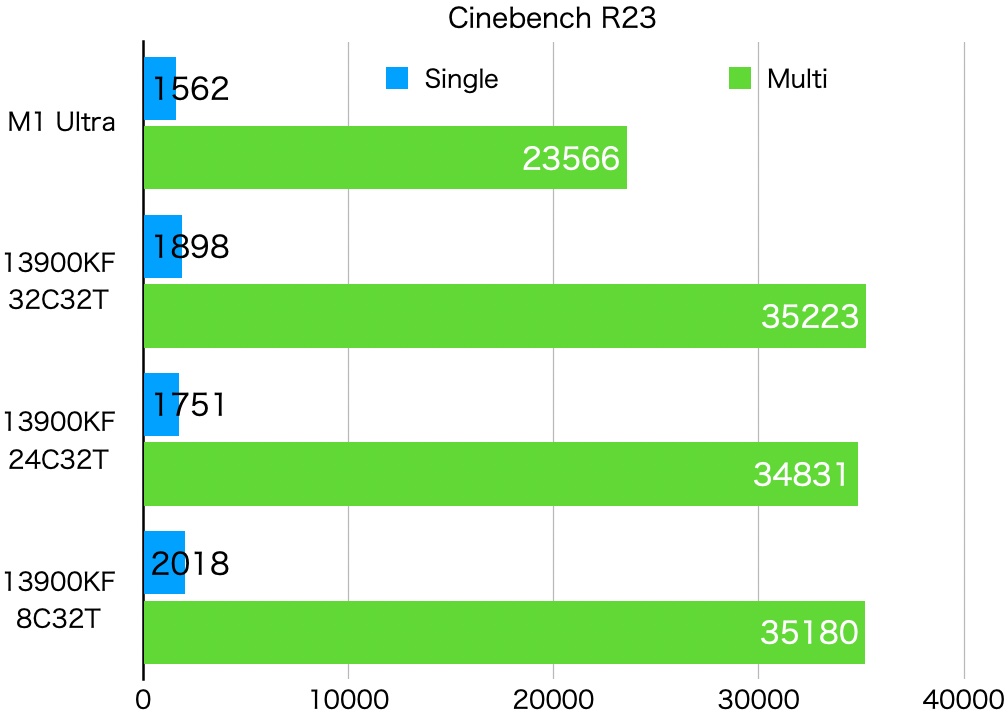

コア構成の比較では、Geekbench 5と同様の傾向が見られました。マルチは32C > 8C > 24Cで、シングルは8C > 32C > 24Cの順番でした。マルチの差は、毎回の測定のばらつきよりも小さいので、誤差範囲かと思います。それでもGeekbenchと同様の傾向だったので、何か意味があるかもしれません。シングルもGeekbenchと同じ傾向でした。これも8Cが一番良い性能でした。
動作の観察
CpuTopologyRebuildの作者の方も考察されてますが、それと同じ結果が得られました。シングルコアの性能は、8C > 32C > 24Cの順に高性能でした。
アクティビティモニターで、Cinebenchシングルスコア測定中のCPUの負荷を観察しました。32個のスレッドの使用状況が棒グラフで表示されます。
まずは32Cの場合の様子です。シングルスコアのベンチマークなので、一度には一つのコアしか使われていないと思いますが、一定時間累積しての表示なのか、複数の棒グラフが反応してました。それを見ると、全部のコアが区別なく使用されているようです。


次は、24Cの場合の様子です。左半分の16本がPコアで、一つおきに本体とそのHTが表示されていると思われます。棒グラフを見ると、そのHTが選択から除外されている様子がわかります。PコアとEコア(おそらく右半分の16本)はあまり区別なく選択されてます。

最後は8Cの場合の様子です。Pコアの物理コア部分のみが選択されてます。右半分のEコアは選択から外れてました。

32Cのシングルコアベンチマークでは、PコアのHTが選択されることもあるので、スコアが下がるのではと予想してました。しかし24Cより好成績でした。想像ですが、HTが選択されても、対応する物理コアが動いていなければ、物理コアと同等の性能が出せるのかもしれません。その結果、作者の方の分析通り、Pコアが選択される確率の高い32Cの方が24Cよりも好成績になったのかと思われます。
ちなみに、マルチコアのベンチマーク時は、どのコア設定でも大差ありませんでした。CPU使用状況を見ると、ほぼどのスレッドもフルに稼働しています。重い作業をさせるベンチマークテストでは、スレッド優先順位が適切に設定されていても、結局は全てのスレッド総出で使用されるので、差が出ないのかと思いました。

まとめ
13900KFのコア数設定を調整するCpuTopologyRebuild.kextを使ってみました。物理コアとハイパースレッド (HT) の数をmacOSに適切に伝えるためのkextです。ベンチマークテストで比較した結果、argで-ctrsmtをつけてこのkextを使い、物理コア8に設定することで、より良い性能を得られました。素晴らしいkextを作っていただきありがとうございます。
